

Quick Summary
A robots.txt file is used to manage web crawler access to your website. It plays a key role in website indexing by controlling which parts of your site are visible to search engine bots. This guide will help you understand what is robots.txt, its benefits for robots.txt SEO, and how to create and optimize one for your site. Learn about crawl directives, disallow directives, and sitemap inclusion to improve your site’s performance.
Understanding what is robots.txt is essential for anyone looking to improve their site’s SEO and control web crawler access. A robots.txt file serves as a set of instructions for search engine bots, guiding them on which parts of your site they are allowed to crawl and index. This is achieved through crawl directives that manage the interaction between your website and the bots.
The robot exclusion protocol was first introduced in 1994, making robots.txt almost 30 years old. Its primary function is to block unwanted bots and search engines from accessing certain parts of your website. This protocol has been instrumental in helping webmasters control and optimize their site’s visibility on search engines.
In this robots.txt guide, we will cover the following topics:
- A detailed definition of robots.txt and its role in web crawling.
- How robots.txt works, including its syntax and structure.
- Steps to create and configure a robots.txt file.
- The importance of robots.txt in SEO.
- Common mistakes to avoid when using robots.txt.
- A conclusion summarizing the significance of maintaining a well-configured robots.txt file.
By the end of this guide, you’ll have a clear understanding of how to use robots.txt effectively to enhance your site’s SEO and manage web crawler access.
What is Robots.txt?
A robots.txt file is a simple text file located at the root of your website that communicates with web crawlers and search engine bots. Its primary purpose is to instruct these bots on which parts of the site they can access and index. This file plays a significant role in website indexing and helps improve your site’s SEO by controlling bot traffic effectively.
The robot exclusion protocol, established in 1994, forms the foundation of robots.txt. This protocol was designed to provide a straightforward method for webmasters to manage bot access to their sites. By using crawl directives such as “User-agent” and “Disallow,” webmasters can guide bots on how to interact with their websites.
Detailed Definition and Role in Web Crawling
At its core, robots.txt serves as a set of rules for bots. These rules are defined using specific directives that indicate what is allowed and what is not. Here’s a breakdown of the primary components of a robots.txt file:
- User-agent: This directive specifies the bot the rule applies to. For example, “User-agent: Googlebot” targets Google’s search engine bot.
- Disallow: This directive tells the specified bot which parts of the site should not be accessed. For instance, “Disallow: /admin” prevents bots from crawling the admin section of the site.
- Allow: This directive can be used to override a “Disallow” directive and permit access to specific parts of a disallowed section.
- Sitemap: This directive provides the location of the site’s XML sitemap, aiding in sitemap inclusion and enhancing the efficiency of bots during indexing.
Differences Between Robots.txt and Meta Robots Tags
| Aspect | Robots.txt | Meta Robots Tags |
|---|---|---|
| Definition | A text file at the root of your website that provides directives to web crawlers. | HTML tags within individual web pages that provide instructions to web crawlers. |
| Location | Root directory of the website. | Inside the HTML of each web page. |
| Control Level | Server-level control, can block entire sections of the site. | Page-level control, can provide granular instructions for individual pages. |
| Directives | User-agent, Disallow, Allow, Sitemap. | index, noindex, follow, nofollow, noarchive, nosnippet. |
| Use Case | Blocking access to entire directories or sections of the site. | Controlling indexing and link-following behavior for specific pages. |
| Implementation | Requires creating and editing a single text file. | Requires adding tags to the HTML code of individual pages. |
Understanding what is robots.txt and its proper configuration is crucial for optimizing robots.txt SEO. By effectively using crawl directives, you can improve your site’s visibility and ensure that search engine bots access only the most relevant parts of your site.
How Does Robots.txt Work?
Understanding how robots.txt functions is crucial for optimizing your website’s interaction with web crawlers and enhancing your robots.txt SEO efforts. This file operates through a set of directives that instruct search engine bots on which parts of your site they can access and index.
Interaction with Web Crawlers
When a web crawler visits your site, it first looks for the robots.txt file in the root directory. If found, the crawler reads the directives listed in the file to determine which parts of the site it can crawl. These directives include User-agent, Disallow, Allow, and Sitemap.
- User-agent: Specifies the web crawler to which the rule applies. For example, “User-agent: Googlebot” targets Google’s crawler specifically.
- Disallow: Instructs the specified user-agent not to crawl certain parts of the site. For instance, “Disallow: /admin” prevents the bot from accessing the admin section.
- Allow: Overrides a Disallow directive, allowing access to specific parts of a disallowed section.
- Sitemap: Indicates the location of your XML sitemap, facilitating sitemap inclusion for better indexing.
Syntax and Structure
A robots.txt file is structured in a way that each group of directives starts with a user-agent line, followed by one or more Disallow or Allow lines. Here is an example:
User-agent: Googlebot
Disallow: /private/
Allow: /public/
User-agent: *
Disallow: /tmp/
Sitemap: https://www.example.com/sitemap.xmlIn this example:
- Googlebot is blocked from accessing the /private/ directory but allowed to access the /public/ directory.
- All other bots (denoted by the wildcard *) are blocked from the /tmp/ directory.
- The sitemap directive helps search engines locate the site’s XML sitemap.
Common Directives
- Disallow: Prevents bots from accessing specified directories or files.
Disallow: /example/- Allow: Grants access to certain files within a disallowed directory.
Allow: /example/specific-file.html- Sitemap: Lists the URL of the sitemap to aid in indexing.
Sitemap: https://www.example.com/sitemap.xml- Crawl-delay: Tells the bot to wait a certain amount of time between requests to avoid overloading the server. Note that Google does not support this directive; it is mainly used by Bing and Yandex.
Crawl-delay: 10Using these directives effectively can significantly improve your site’s SEO by managing how search engine bots interact with your content. Proper configuration ensures that important pages are indexed while sensitive or irrelevant sections are not crawled, optimizing your site’s website indexing strategy.
Creating and Configuring a Robots.txt File
Creating and configuring a robots.txt file is essential for controlling how web crawlers interact with your website. This guide will help you set up your robots.txt file correctly to optimize robots.txt SEO.
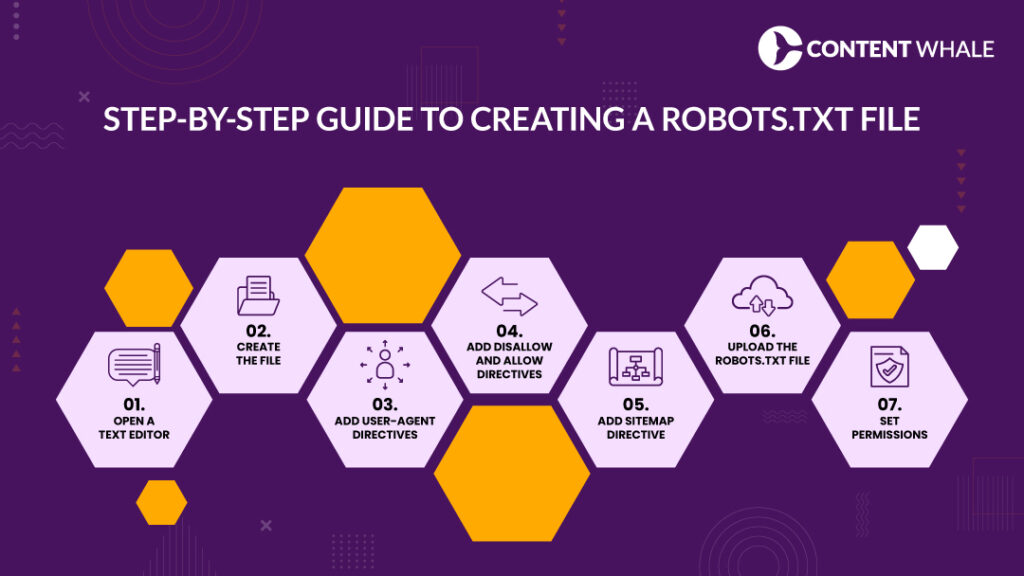
Step-by-Step Guide to Creating a Robots.txt File
1. Open a Text Editor:
- Use a simple text editor like Notepad (Windows) or TextEdit (Mac). Ensure the file is saved with UTF-8 encoding.
2. Create the File:
- Name the file “robots.txt”.
3. Add User-Agent Directives:
- Specify which web crawlers the directives apply to.
- Example:
User-agent: Googlebot
Disallow: /private/
Allow: /public/4. Add Disallow and Allow Directives:
- Use the Disallow directive to block crawlers from specific sections.
- Use the Allow directive to grant access to specific parts within disallowed sections.
- Example:
User-agent: *
Disallow: /tmp/
Allow: /tmp/public-file.html5. Add Sitemap Directive:
- Including the sitemap directive helps search engines locate your sitemap for efficient indexing.
- Example:
Sitemap: https://www.example.com/sitemap.xml6. Upload the Robots.txt File:
- Save and upload the robots.txt file to the root directory of your website (e.g., https://www.yourdomain.com/robots.txt).
7. Set Permissions:
- Ensure the file permissions allow web crawlers to read it. Typically, this is 644.
Tools and Resources
- CMS Platforms: Many CMS platforms like WordPress, Magento, and Wix generate basic robots.txt files. You can customize these files using plugins like Yoast or All in One SEO Pack.
- Online Generators: Tools like SE Ranking’s Robots.txt Generator can help you create a custom robots.txt file.
- Google Search Console: Use the robots.txt Tester to check your file for errors and validate its directives.
Best Practices
1. New Line for Each Directive:
Each directive should be on a separate line to avoid confusion.
- Example:
Disallow: /blog/
Disallow: /contact/2. Use Wildcards and Dollar Signs:
- Wildcards (*) simplify instructions by applying rules to multiple URLs.
- The dollar sign ($) specifies the end of a URL pattern.
- Example:
Disallow: /*.jpg$3. Avoid Blocking Important Content:
- Ensure that critical pages like the homepage or product pages are not accidentally disallowed.
4. Don’t Block CSS and JavaScript Files:
- Allow search engines to access CSS and JavaScript files to understand your site structure and functionality.
- Example:
Allow: /css/
Allow: /js/Use Comments for Clarity:
- Add comments to explain the purpose of specific directives.
- Example:
Disallow: /private/ # Block private directoryTesting and Maintenance
Regularly test and maintain your robots.txt file using Google Search Console or similar tools to ensure it functions correctly and adheres to best practices.
Importance of Robots.txt in SEO

The robots.txt file is a fundamental tool for managing how web crawlers interact with your website, significantly impacting your robots.txt SEO strategy. This simple text file helps control which parts of your site are crawled and indexed by search engine bots, playing a crucial role in optimizing your site’s visibility and performance.
How Robots.txt Impacts SEO
1. Crawl Budget Management:
Crawl budget refers to the number of pages a search engine bot will crawl on your site within a given timeframe. By using crawl directives in your robots.txt file, you can direct bots to prioritize important pages, ensuring that the most valuable content is indexed. For instance, you might disallow bots from crawling low-value pages like admin sections or duplicate content.
2. Preventing Duplicate Content:
Duplicate content can negatively affect your site’s SEO. The robots.txt guide allows you to block search engines from indexing certain pages, thus preventing duplicate content issues. This is particularly useful for blocking parameters in URLs that might create duplicate content.
3. Protecting Sensitive Information:
You can use the disallow directives in robots.txt to prevent search engines from accessing and indexing sensitive areas of your site, such as login pages or private directories. This helps maintain the security and privacy of your site’s content.
4. Optimizing Server Resources:
By controlling which pages are crawled, robots.txt helps manage your server load. This is especially important for large sites where excessive crawling can slow down the server and affect user experience. Implementing a crawl-delay directive can further help manage server load by instructing bots to wait for a specified time between requests.
5. Guiding Search Engine Bots:
Properly configured robots.txt files ensure that search engine bots focus on the most relevant parts of your site. Including a sitemap directive in your robots.txt file can help search engines locate your sitemap, improving the efficiency of the crawling and indexing process.
Best Practices for Robots.txt
1. Case Sensitivity:
The robots.txt file is case-sensitive. Ensure all directives are correctly capitalized to avoid errors.
2. Placement:
Place your robots.txt file in the root directory of your site (e.g., https://www.example.com/robots.txt) to ensure it is found by search engines.
3. Use of Wildcards:
Utilize wildcards (*) to apply rules to multiple URLs and the dollar sign ($) to specify the end of a URL. For example, to block all PDF files, you can use:
User-agent: *
Disallow: /*.pdf$4. Testing and Validation:
Regularly test and validate your robots.txt file using tools like Google Search Console to ensure it is functioning as intended and to identify any errors.
By following these best practices, you can leverage the robots.txt file to enhance your SEO strategy, ensuring that your site’s most important content is efficiently crawled and indexed while protecting sensitive information and optimizing server performance.
Common Mistakes and How to Avoid Them

Creating a robots.txt file is crucial for managing how search engine bots interact with your website. However, common mistakes can lead to issues with website indexing and negatively impact your SEO. Here’s how to avoid these pitfalls.
Overblocking Important Pages
Overblocking is a common mistake where important pages get inadvertently blocked, harming your site’s SEO. For instance, using a broad disallow directive might block more pages than intended.
Solution: Use specific paths and test your robots.txt directives regularly. Example:
User-agent: *
Disallow: /private/
Allow: /private/public-file.htmlThis setup ensures that only the intended pages are blocked while allowing access to specific files.
Incorrect Syntax and Misconfigured Wildcards
Syntax errors and misconfigured wildcards can lead to search engine bots misinterpreting your directives. For example, not using a trailing slash properly can block more than intended.
Solution: Ensure correct syntax and proper use of wildcards. Example:
User-agent: *
Disallow: /private/
Allow: /private/subdirectory/Regularly validate your file using tools like Google’s Robots Testing Tool to avoid these issues.
Failing to Update Robots.txt After Site Changes
Neglecting to update your robots.txt file after making changes to your site can result in outdated or incorrect directives.
Solution: Regularly review and update your robots.txt file to reflect any structural changes on your site. This ensures that all directives are current and effective.
Blocking CSS and JavaScript Files
Accidentally blocking CSS and JavaScript files can prevent search engines from properly rendering your site, leading to indexing issues.
Solution: Ensure that your robots.txt guide includes directives to allow CSS and JavaScript files:
Allow: /css/
Allow: /js/This helps search engines understand your site’s structure and functionality better.
Ignoring Case Sensitivity
URLs and directives in robots.txt are case-sensitive. Misusing case can lead to unexpected results.
Solution: Always use the correct case in your directives. Example:
User-agent: *
Disallow: /Private/Make sure to use consistent case to avoid blocking the wrong URLs.
Using Deprecated Directives
Some directives, like noindex, are no longer supported in robots.txt. Using outdated directives can cause search engines to ignore parts of your file.
Solution: Use current standards and best practices. Instead of using noindex in robots.txt, use meta tags or HTTP headers. Example:
<meta name="robots" content="noindex">or
- X-Robots-Tag: noindex
Regularly review updates from major search engines to stay compliant.
By avoiding these common mistakes, you can ensure that your robots.txt file effectively manages web crawler access, improves your robots.txt SEO, and optimizes your site’s performance.
Conclusion

A well-configured robots.txt file is essential for managing how search engine bots interact with your website. This small but powerful text file helps ensure that your website’s most important content is crawled and indexed while preventing access to sensitive or irrelevant sections.
Understanding what is robots.txt and its role in SEO is crucial. By using crawl directives, you can control the visibility of your site’s content to web crawlers, ensuring that only the most relevant pages are indexed. This helps in optimizing your robots.txt SEO and improving overall site performance.
Regularly reviewing and updating your robots.txt file is vital. As your site evolves, so should your robots.txt directives. Use tools like Google Search Console to test and validate your file, ensuring it remains error-free and effective.
Balancing crawl accessibility with security and relevance is key. By following best practices and avoiding common mistakes, you can make the most of your robots.txt and enhance your site’s SEO strategy. Remember, while robots.txt is powerful, it should be used thoughtfully to avoid unintentional SEO issues.
FAQs
What is a robots.txt file and why is it important?
A robots.txt file instructs web crawlers on which parts of your site they can access and index, helping manage website indexing and improving SEO.
How do I create and configure a robots.txt file?
Create a text file named “robots.txt” and upload it to your site’s root directory. Use directives like User-agent, Disallow, Allow, and Sitemap to control bot access.
What are common mistakes to avoid with robots.txt?
Avoid overblocking, incorrect syntax, failing to update the file, and blocking essential resources like CSS and JavaScript files.
How does robots.txt affect SEO and website indexing?
Properly configured robots.txt helps manage crawl budgets, prevents duplicate content, and protects sensitive information, enhancing your site’s SEO.
Can I use robots.txt to block all web crawlers from my site?
Yes, you can use a directive like User-agent: * Disallow: / to block all web crawlers, but this is generally not recommended unless necessary.




 Content Whale – USA
Content Whale – USA